Julian Straub

Julian Straub is a Research Scientist at Meta Reality Labs Research (RLR) working on Computer Vision and 3D Perception. Before joining RLR, Julian obtained his PhD on Nonparametric Directional Perception from MIT, where he was advised by John W. Fisher III and John Leonard within the CS and AI Laboratory (CSAIL). On his way to MIT, Julian graduated from the Technische Universität München (TUM) and the Georgia Institute of Technology with a M.Sc. He did his Diploma thesis in Eckehard Steinbach’s group with the NavVis founding team and in particular with Sebastian Hilsenbeck. At Georgia Tech Julian had the pleasure to work with Frank Daellart’s group.
Scholar Github LinkedIn X Resume Email
Research
My current research interests are problems that involve 3D localization, recognition and description of all objects and surfaces from egocentric video streams in scalable and generalizable ways.
Here are some recent invited talks:
- ICCV 2025 OpenSUN3D Workshop (slides)
- CVPR 2025 Point Cloud Tutorial (page)
- ECCV 2024 Spatial AI Workshop (slides)
- ECCV 2024 Egocentric Research Tutorial with Project Aria (talk)
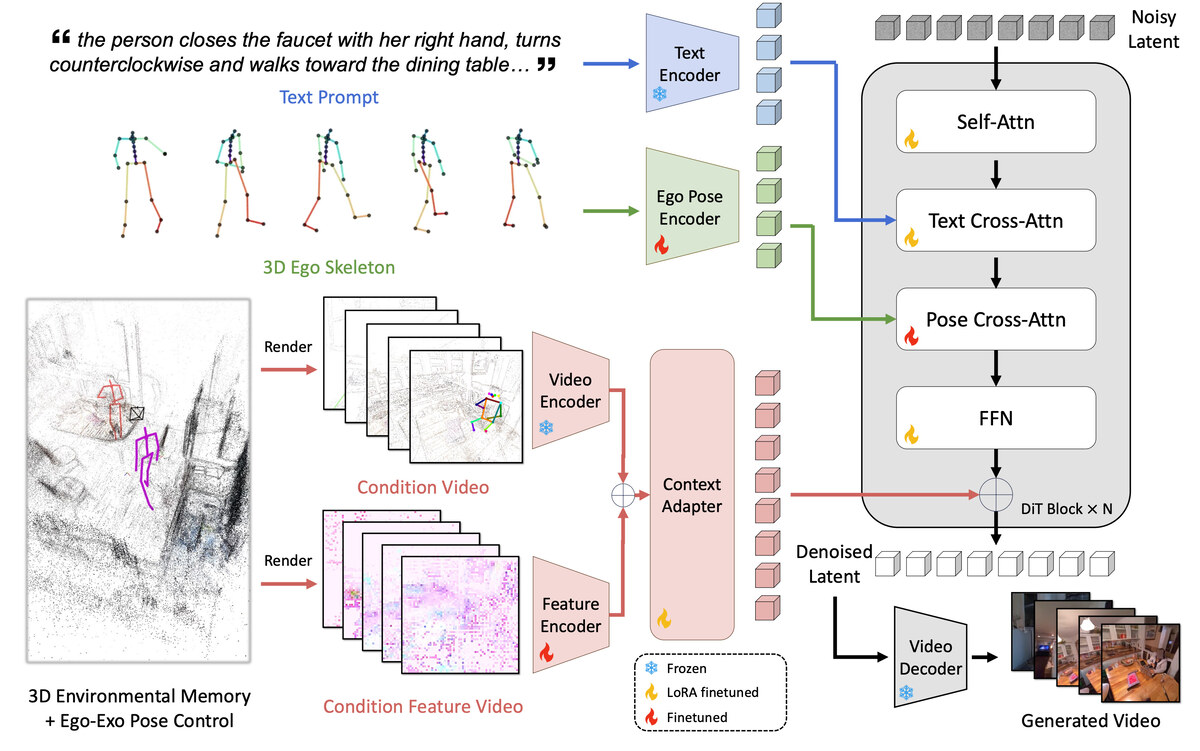
Qiao Gu, Lingni Ma, Adam W. Harley, Richard Newcombe, Florian Shkurti, Julian Straub
E3C generates controllable, physically grounded egocentric video by disentangling persistent scene structure from human-driven dynamics. It builds a semi-dense point-cloud 3D memory of the environment and renders ego- and exo-skeletons for human pose control, improving visual fidelity, camera-motion accuracy, object consistency, and human control.
Nan Yang, Julian Straub, Fan Zhang, Richard Newcombe, Jakob Engel, Lingni Ma
LAMP lifts 2D body keypoints from all cameras into a shared 3D world frame using known device pose and calibration, then fits 3D human motion to this ray cloud with a spatio-temporal transformer. This “lift-then-fit” approach sets a new state of the art on both monocular and egocentric benchmarks.
Daniel DeTone, Tianwei Shen, Fan Zhang, Lingni Ma, Julian Straub, Richard Newcombe, Jakob Engel
Arxiv 04/2026 project page code model
BoxerNet lifts 2D bounding box proposals to 3D given gravity and optional sparse or dense depth, and Boxer fuses them across views into globally consistent, de-duplicated 3D boxes in metric world space. Building on off-the-shelf 2D detectors, it localizes open-world objects in 3D.

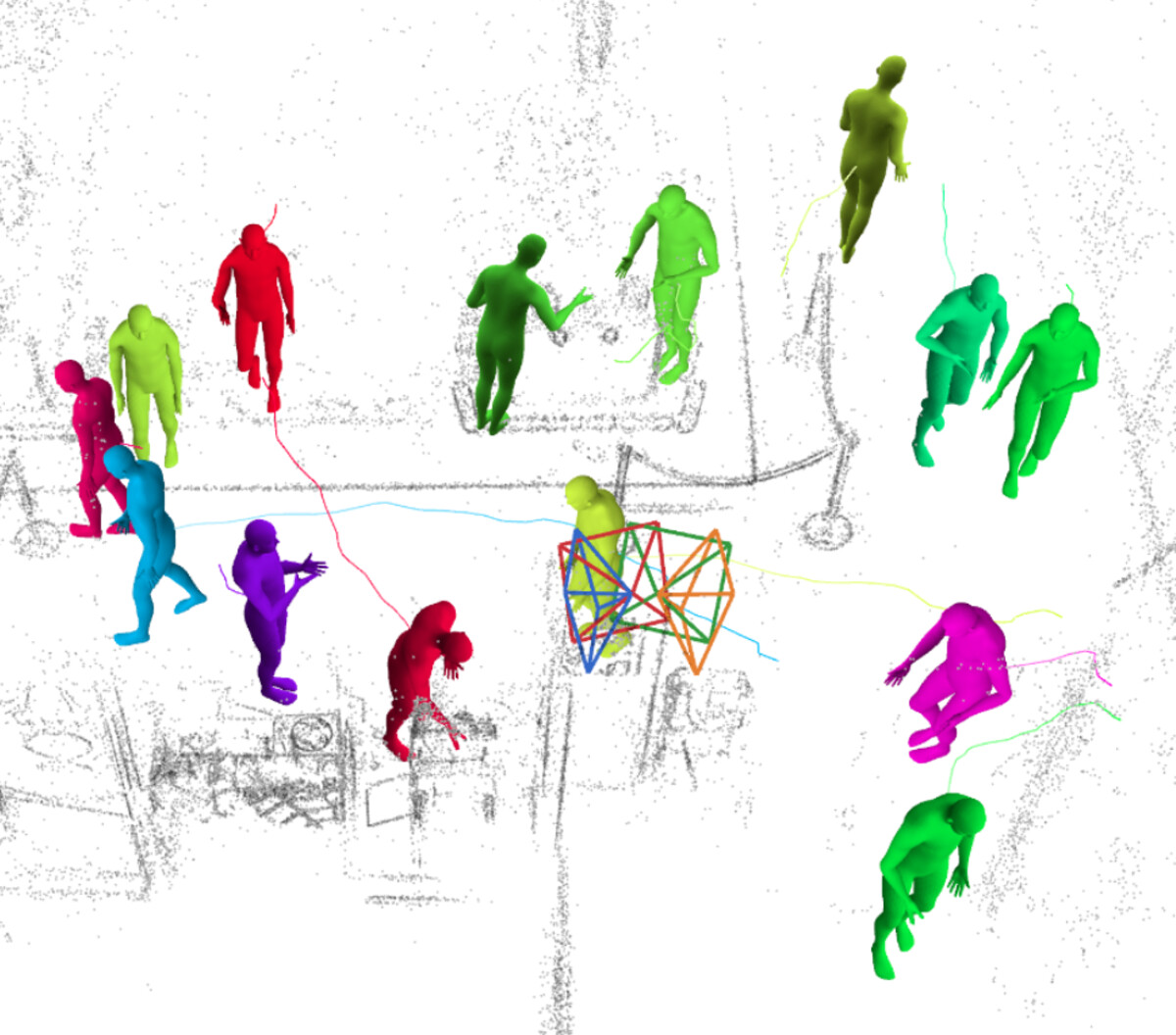
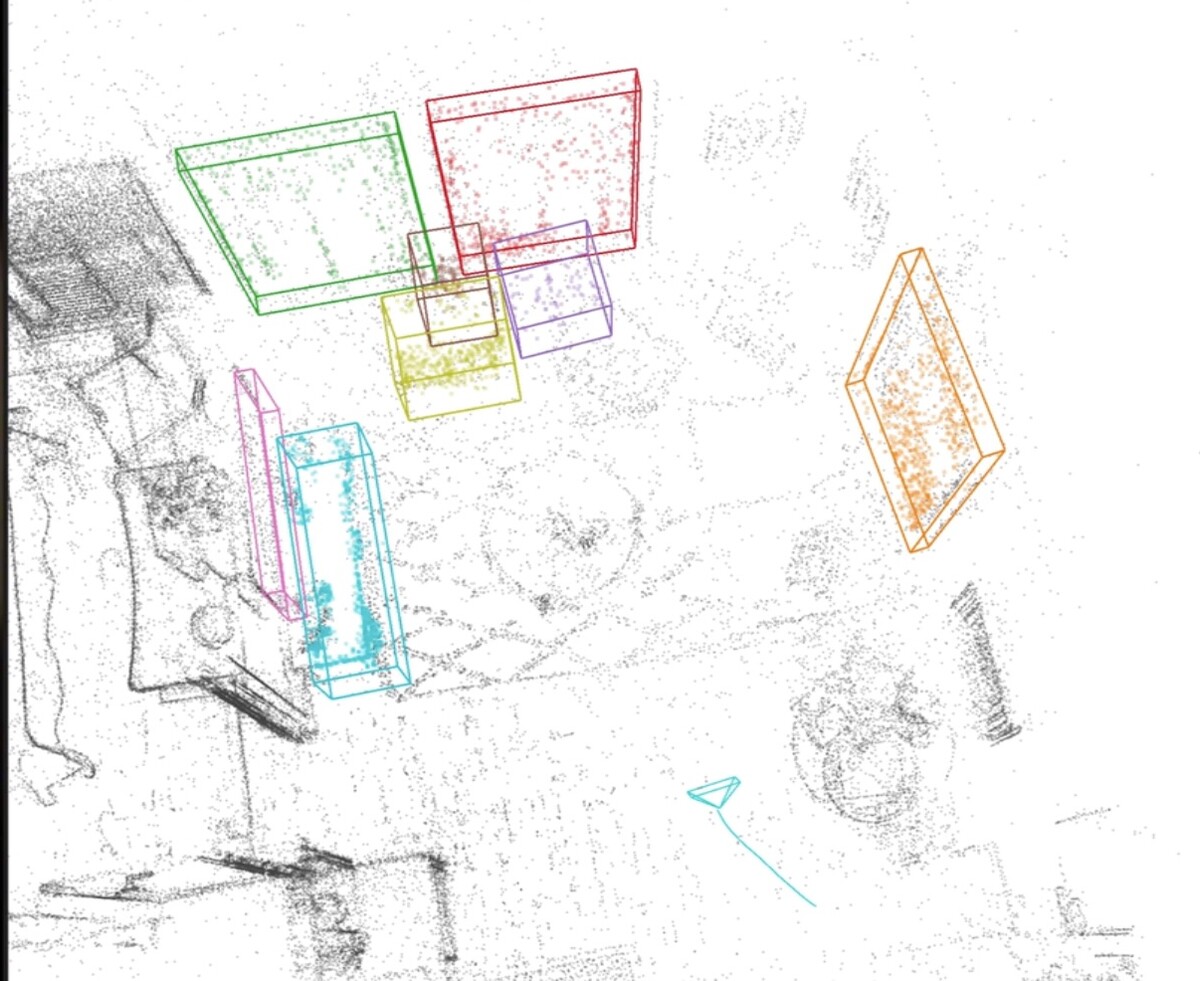
Daniel DeTone, Federica Bogo, Eric-Tuan Le, Duncan Frost, Julian Straub, Yawar Siddiqui, Yuting Ye, Jakob Engel, Richard Newcombe, Lingni Ma
An upgrade of the egocentric Nymeria dataset, adding improved human motion (MHR and SMPL), dense 3D and 2D object bounding boxes, instance-level 3D reconstructions, and new modalities such as basemaps, audio, and wristband video.

Yawar Siddiqui, Duncan Frost, Samir Aroudj, Armen Avetisyan, Henry Howard-Jenkins, Daniel DeTone, Pierre Moulon, Qirui Wu, Zhengqin Li, Julian Straub, Richard Newcombe, Jakob Engel
CVPR 2026 project page github video weights
ShapeR generates high-fidelity 3D shapes from casually captured image sequences. It uses SLAM, 3D detection, and vision-language models to extract per-object conditioning and a rectified flow transformer to generate shapes, achieving 2.7x improvement in Chamfer distance over state of the art.

Chen Kong, James Fort, Aria Kang, Jonathan Wittmer, Simon Green, Tianwei Shen, Yipu Zhao, Cheng Peng, Gustavo Solaira, Andrew Berkovich, Nikhil Raina, Vijay Baiyya, Evgeniy Oleinik, Eric Huang, Fan Zhang, Julian Straub, Mark Schwesinger, Luis Pesqueira, Xiaqing Pan, Jakob Engel, Carl Ren, Mingfei Yan, Richard Newcombe
Arxiv 10/2025 dataset explorer
An egocentric multimodal dataset recorded with Aria Gen 2 glasses covering daily activities including cleaning, cooking, eating, playing, and outdoor walking. Includes raw sensor data and machine perception outputs.

Chieh Hubert Lin, Zhaoyang Lv, Songyin Wu, Zhen Xu, Thu Nguyen-Phuoc, Hung-Yu Tseng, Julian Straub, Numair Khan, Lei Xiao, Ming-Hsuan Yang, Yuheng Ren, Richard Newcombe, Zhao Dong, Zhengqin Li
A feed-forward method for real-time reconstruction of dynamic scenes from monocular video. DGS-LRM predicts deformable 3D Gaussians in a single forward pass, achieving results competitive with optimization-based methods while enabling long-range 3D object tracking.

Xiaoyang Wu, Daniel DeTone, Duncan Frost, Tianwei Shen, Chris Xie, Nan Yang, Jakob Engel, Richard Newcombe, Hengshuang Zhao, Julian Straub,
CVPR 2025 project page github weights
Self-supervised learning of powerful and reliable point cloud representations. Sonata features improve linear probing accuracy by 3x on ScanNet and performance by 2x when given only 1% of training data.
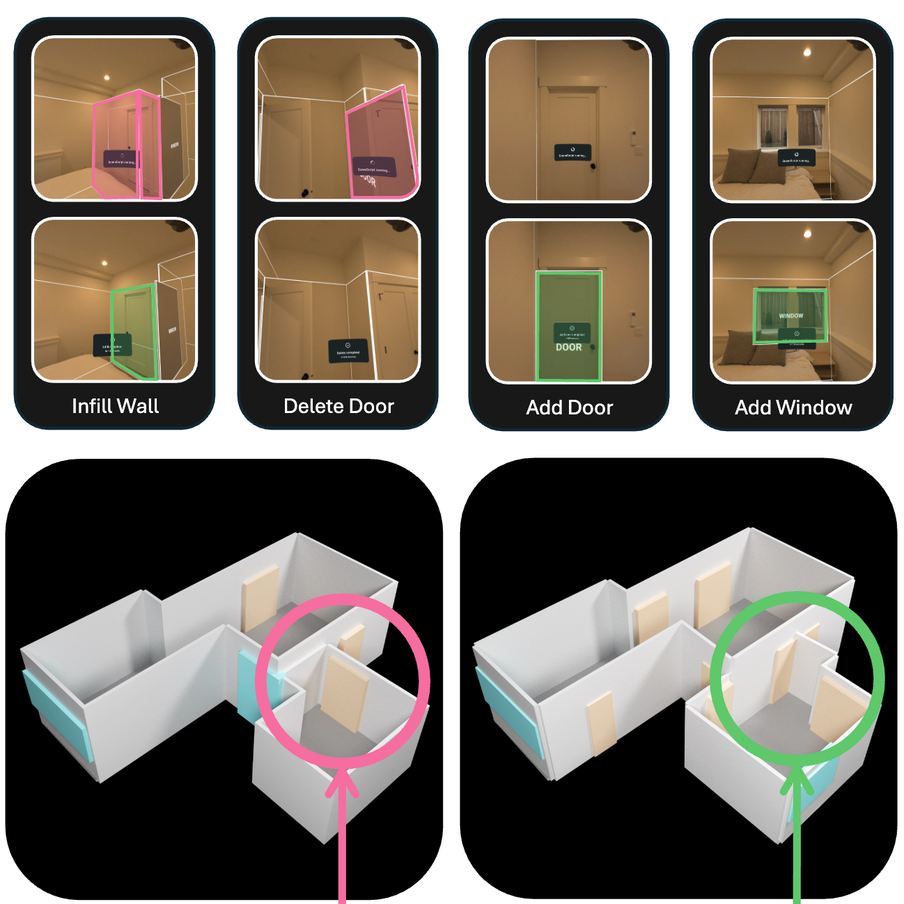
Chris Xie, Armen Avetisyan, Henry Howard-Jenkins, Yawar Siddiqui, Julian Straub, Richard Newcombe, Vasileios Balntas, Jakob Engel
A system for interactively refining 3D scene layout estimates through human feedback. By framing local corrections as an infilling task on top of SceneScript, the model enables targeted refinements while maintaining global prediction quality.

Julian Straub, Daniel DeTone, Tianwei Shen, Nan Yang, Chris Sweeney, Richard Newcombe
Arxiv 06/2024 github slides talk
The EFM3D benchmark measures progress on egocentric 3D reconstruction and 3D object detection. This accelerates research on a novel class of egocentric foundation models rooted in 3D space. A new model, EVL, establishes the first baseline for the benchmark.

Qiao Gu, Zhaoyang Lv, Duncan Frost, Simon Green, Julian Straub, Chris Sweeney
We show how to reconstruct and instance segment egocentric Project Aria data using Gaussian Splats.
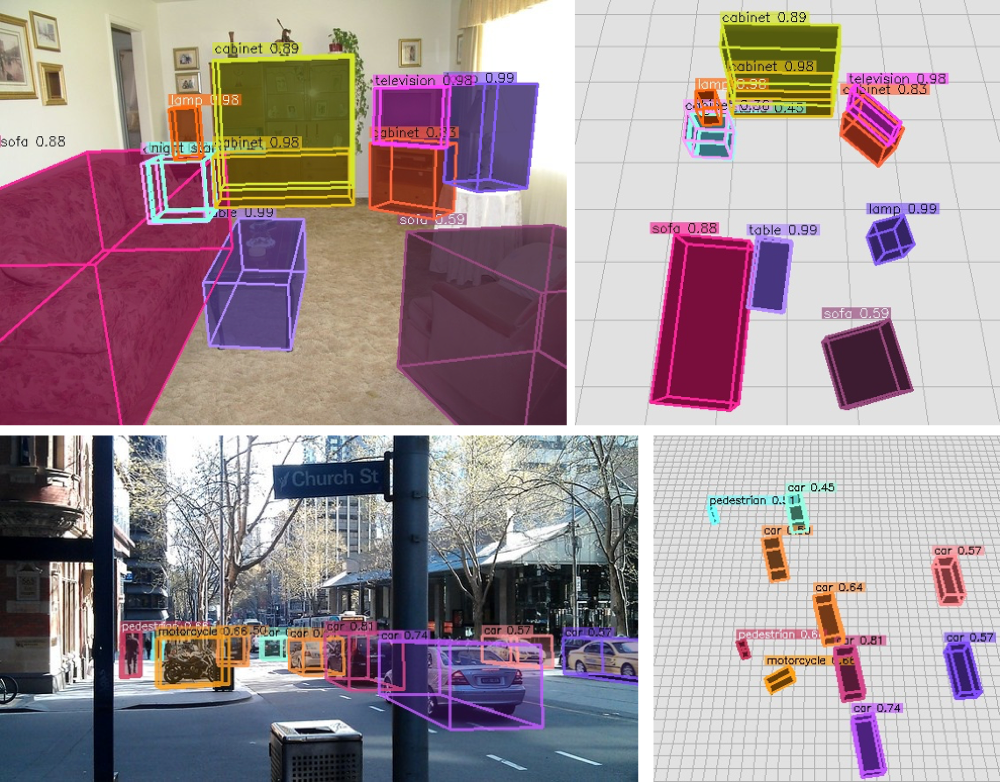
Garrick Brazil, Abhinav Kumar, Julian Straub, Nikhila Ravi, Justin Johnson, Georgia Gkioxari
Omni3D repurposes and combines existing datasets resulting in 234k images annotated with more than 3 million instances and 98 categories. We propose a model, called Cube R-CNN, designed to generalize across camera and scene types with a unified approach.

Paul-Edouard Sarlin, Daniel DeTone, Tsun-Yi Yang, Armen Avetisyan, Julian Straub, Tomasz Malisiewicz, Samuel Rota Bulo, Richard Newcombe, Peter Kontschieder, Vasileios Balntas
We introduce the first deep neural network that can accurately localize an image using the same 2D semantic maps that humans use to orient themselves. OrienterNet leverages free and global maps from OpenStreetMap and is thus more accessible and more efficient than existing approaches.
Yiming Xie, Huaizu Jiang, Georgia Gkioxari, Julian Straub
PARQ detects 3D oriented bounding boxes of objects from short posed video sequences.

Jakob Engel, Kiran Somasundaram, Michael Goesele, …, Julian Straub, … Richard Newcombe
The Project Aria device from my team at Meta Reality Labs Research is an egocentric, multi-modal data recording and streaming device with the goal to foster and accelerate research. Join Project Aria.
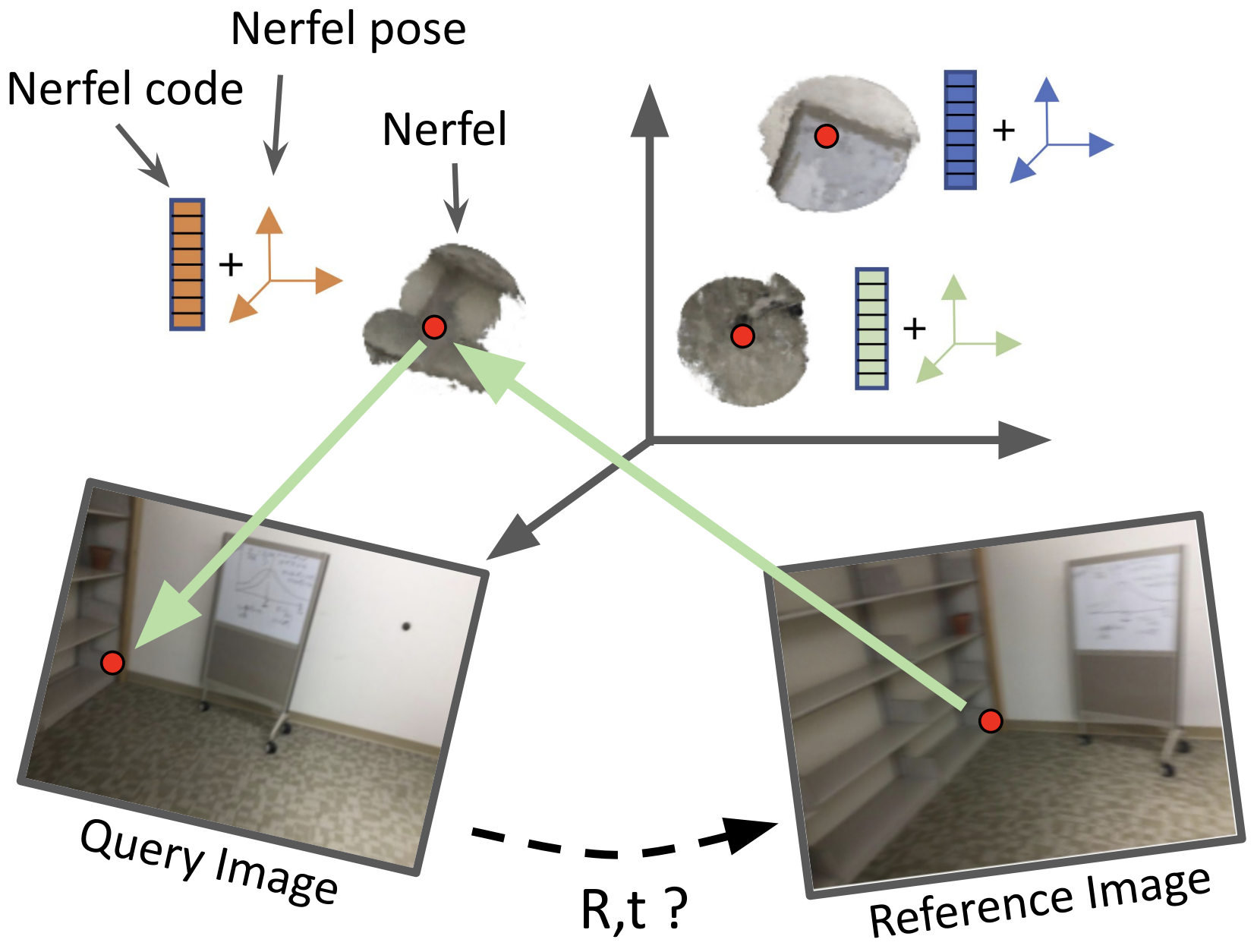
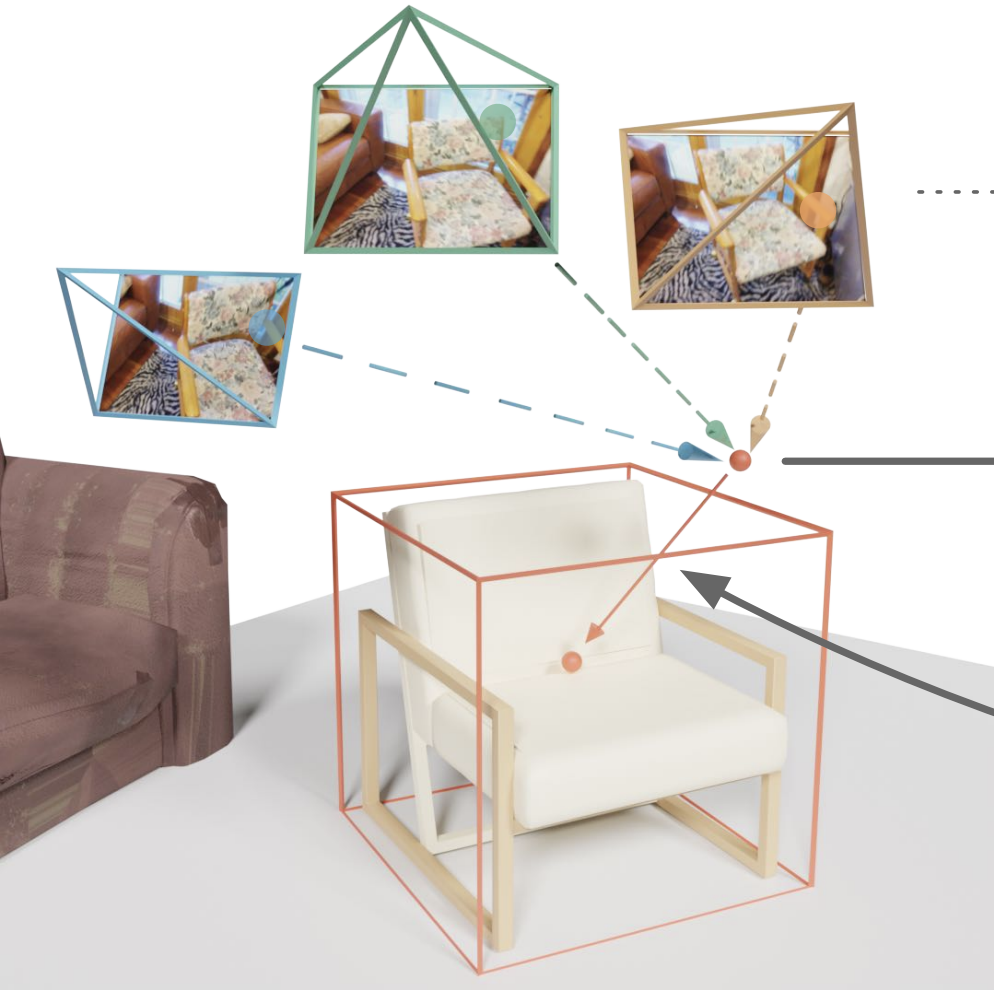
Gil Avraham, Julian Straub, Tianwei Shen, Tsun-Yi Yang, Hugo Germain, Chris Sweeney, Vasileios Balntas, David Novotny, Daniel DeTone, Richard Newcombe
Image Matching Workshop CVPR 2022 workshop
We propose to represent a scene as a set of local Nerfs, which we call Nerfels. Nerfels can be used for wide baseline relocalization.

Kejie Li, Daniel DeTone, Yu Fan Steven Chen, Minh Vo, Ian Reid, Hamid Rezatofighi, Chris Sweeney, Julian Straub, Richard Newcombe
ODAM is trained to detect and track 3D oriented bounding boxes from posed video. We globally optimize a super-quadric-based 3D object representation of the scene.

Martin Runz, Kejie Li, Meng Tang, Lingni Ma, Chen Kong, Tanner Schmidt, Ian Reid, Lourdes Agapito, Julian Straub, Steven Lovegrove, Richard Newcombe
We introduce FroDO, a method for accurate 3D reconstruction of object instances from RGB video that infers their location, pose and shape in a coarse-to-fine manner.
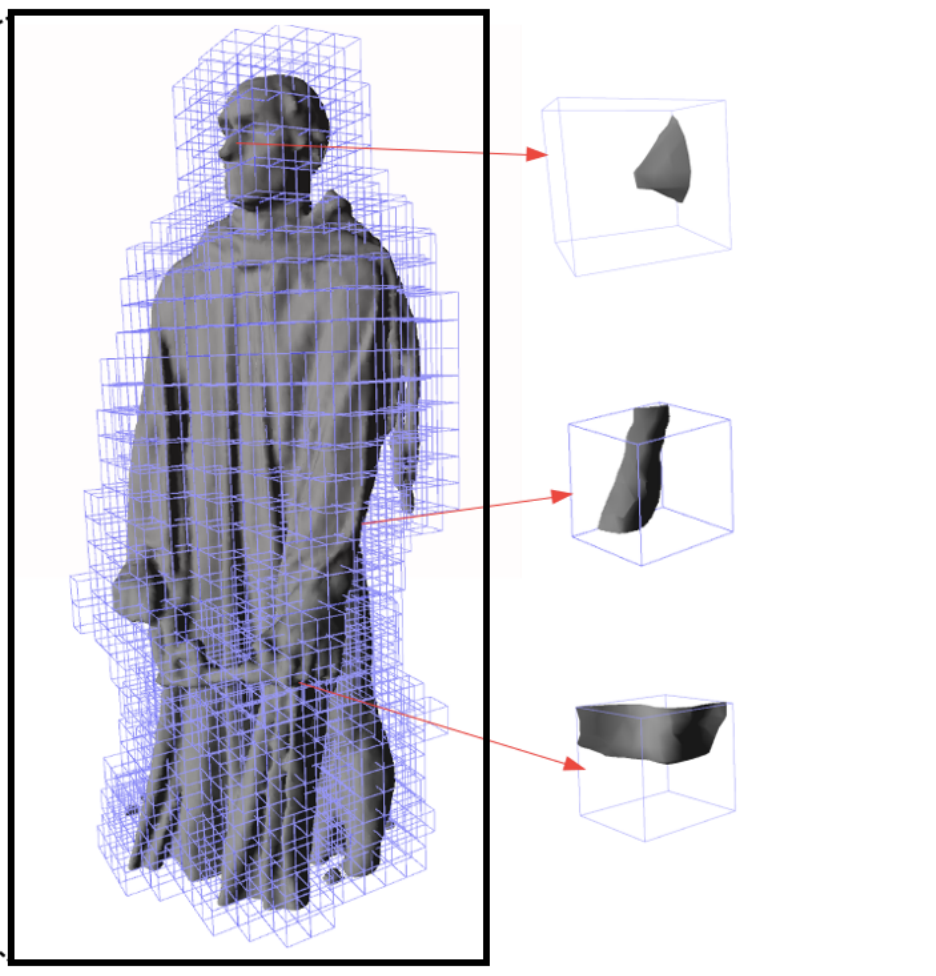
Rohan Chabra, Jan E. Lenssen, Eddy Ilg, Tanner Schmidt, Julian Straub, Steven Lovegrove, Richard Newcombe
Deep Local Shapes (DeepLS) is a deep shape representation that enables encoding and reconstruction of high-quality 3D shapes without prohibitive memory requirements.

Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, Dhruv Batra
We present Habitat, a platform for research in embodied artificial intelligence (AI). Habitat enables training embodied agents (virtual robots) in highly efficient photorealistic 3D simulation.

Rohan Chabra, Julian Straub, Chris Sweeney, Richard Newcombe, Henry Fuchs
StereoDRNet enables the estimation of metrically accurate depth maps enabling high-quality reconstruction by passive stereo video.
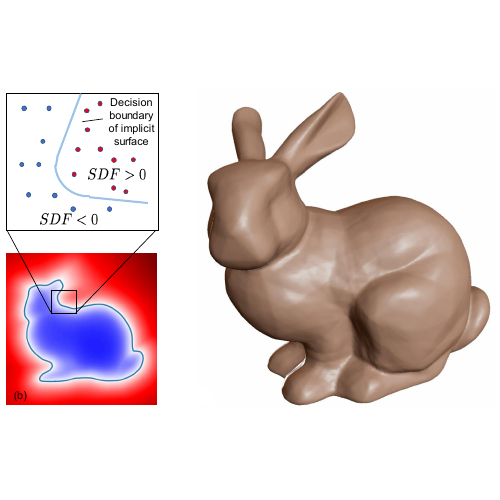
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, Steven Lovegrove
We introduce neural shape representations in the form of a neural network that can be queried for signed distance values (SDFs).

Julian Straub, Thomas Whelan, Lingni Ma, …, Michael Goesele, Steven Lovegrove, Richard Newcombe
The Replica dataset consists of 18 high resolution and high dynamic range (HDR) textured reconstructions with semantic class and instance segmentation as well as planar mirror and glass reflectors.

Thomas Whelan, Michael Goesele, Steven Lovegrove, Julian Straub, Simon Green, Richard Szeliski, Steven Butterfield, Shobhit Verma, Richard Newcombe
We reconstruct mirrors in scenes by detecting a marker on the scanning device. This solves one of the most common failure cases of indoor reconstruction.

Julian Straub, Randi Cabezas, John J. Leonard, John W. Fisher III
Toward fully integrated probabilistic geometric scene understanding, localization and mapping, we propose the first direction-aware, semi-dense SLAM system.

Julian Straub
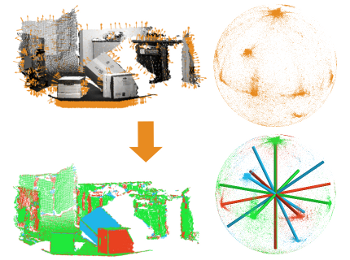
From an indoor scene to large-scale urban environments, a large fraction of man-made surfaces can be described by only a few planes with even fewer different normal directions. This sparsity is evident in the surface normal distributions, which exhibit a small number of concentrated clusters. In this work, I draw a rigorous connection between surface normal distributions and 3D structure, and explore this connection in light of different environmental assumptions to further 3D Perception.
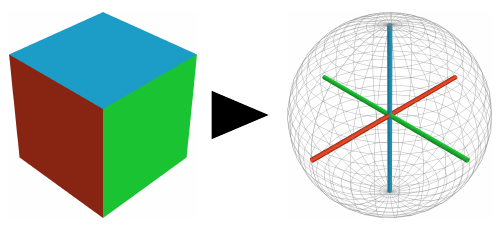
Julian Straub, Oren Freifeld, Guy Rosman, John J. Leonard, John W. Fisher III
We introduce the Manhattan Frame Model which describes the orthogonal pattern of the Manhattan World in the space of surface normals.

Julian Straub
All you want to know about Bayesian inference with von-Mises-Fisher distributions in 3D.
Julian Straub, Trevor Campbell, Jonathan P. How, John W. Fisher III
Use branch-and-bound to globally align two point clouds using nonparametric distribution estimates of their point and normal distributions.

Randi Cabezas, Julian Straub, John W. Fisher III
We propose a probabilistic generative model for inferring semantically-informed aerial reconstructions from multi-modal data within a consistent mathematical framework.
Trevor Campbell, Julian Straub, John W. Fisher III, Jonathan P. How
How to perform Bayesian nonparametric inference on streaming data in a distributed parallelizable way.
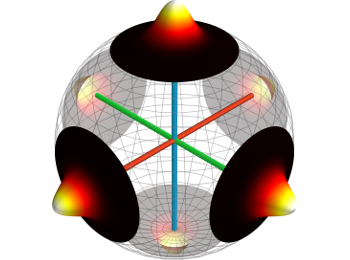
Julian Straub, Nishchal Bhandari, John J. Leonard, John W. Fisher III
We show how to use surface-normals to estimate the global drift-free rotation to a surrounding Manhattan World – a real-time “structure compass”.
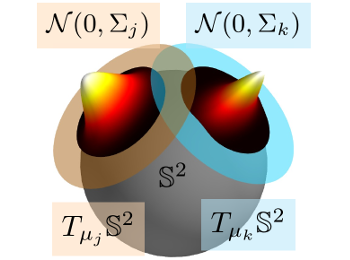
Julian Straub, Jason Chang, Oren Freifeld, John W. Fisher III
We introduce a nonparametric Dirichlet Process mixture model over the sphere via tangent-space Gaussian distributions. This allows modeling complex distributions on the sphere.
Julian Straub, Trevor Campbell, Jonathan P. How, John W. Fisher III
We show how to derive a fast nonparametric DP-means algorithm, DP-vMF-means, for directional data like surface normals. This allows us to analyze surface normal distributions of depth images.
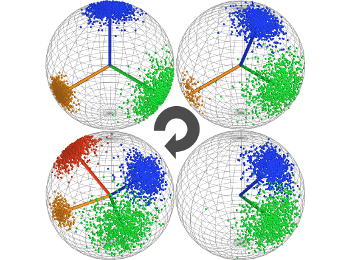
Julian Straub, Guy Rosman, Oren Freifeld, John J. Leonard, John W. Fisher III
We propose a novel probabilistic model that describes the world as a mixture of Manhattan Frames: each frame defines a different orthogonal coordinate system.
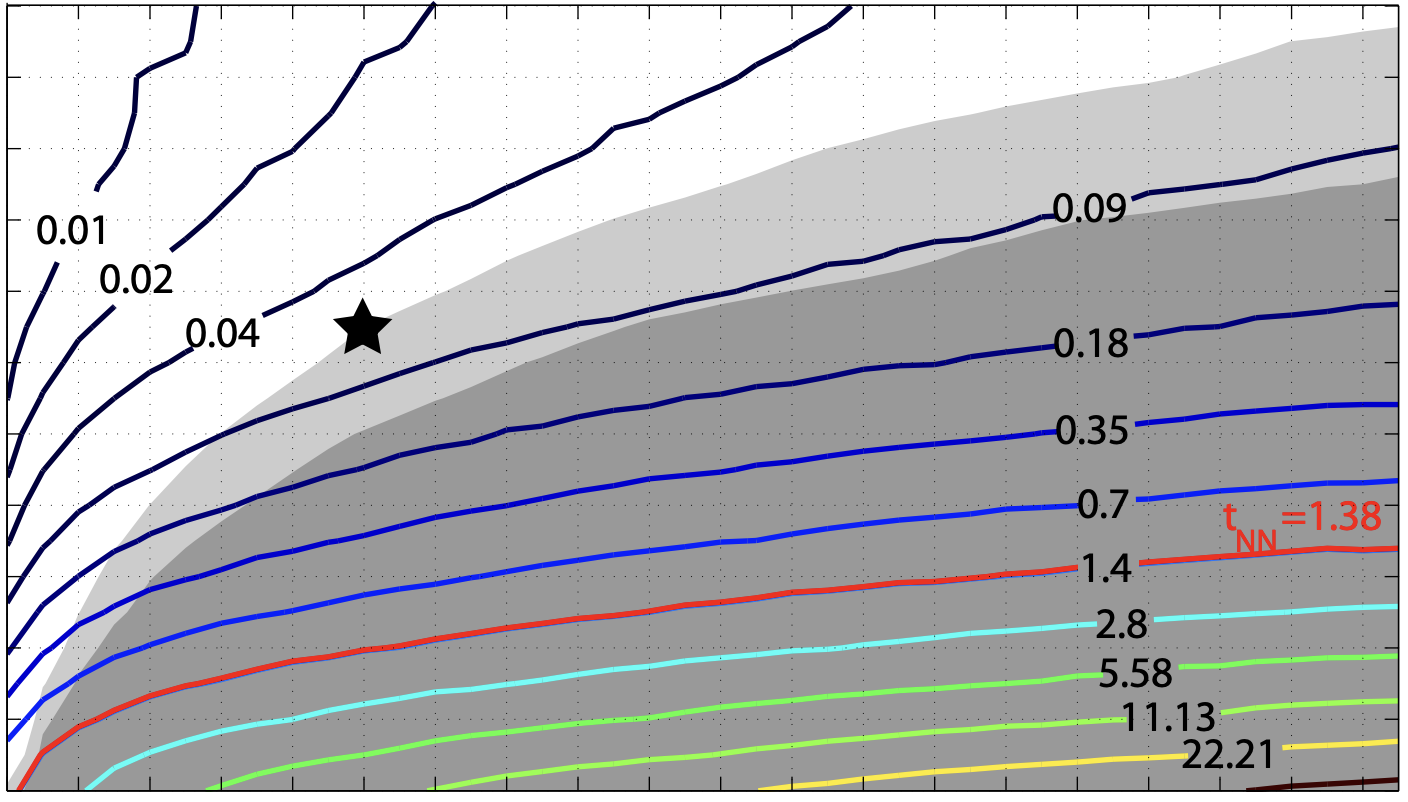
Julian Straub, Sebastian Hilsenbeck, Georg Schroth, Robert Huitl, Andreas Möller, Eckehard Steinbach
We use locality-sensitive hashing to speed up binary feature retrieval for fast camera relocalization.
Writeups
Community Service
Area Chair: CVPR 26*
Reviewing:
- CV:
CVPR15, 18*, 19, 20*, 22–25* ·ICCV23, 25 ·ECCV20, 22, 24 ·TPAMI16–17 - ML:
NeurIPS15, 19, 22–23 ·ICLR23–25 ·AISTATS15 ·ICML15, 24 - Robotics:
ICRA16, 23 ·IROS16
* outstanding reviewer & area chair





